Loading... # 引言 需求:每分钟统计系统信息,包含CPU、内存、网卡、硬盘信息,对于CPU和内存来说,性能指标就那几个,然而对于网卡和硬盘,网卡可能有多个,硬盘可能分区好多种,这样的话,字段设计起来是一件很头痛的事情。 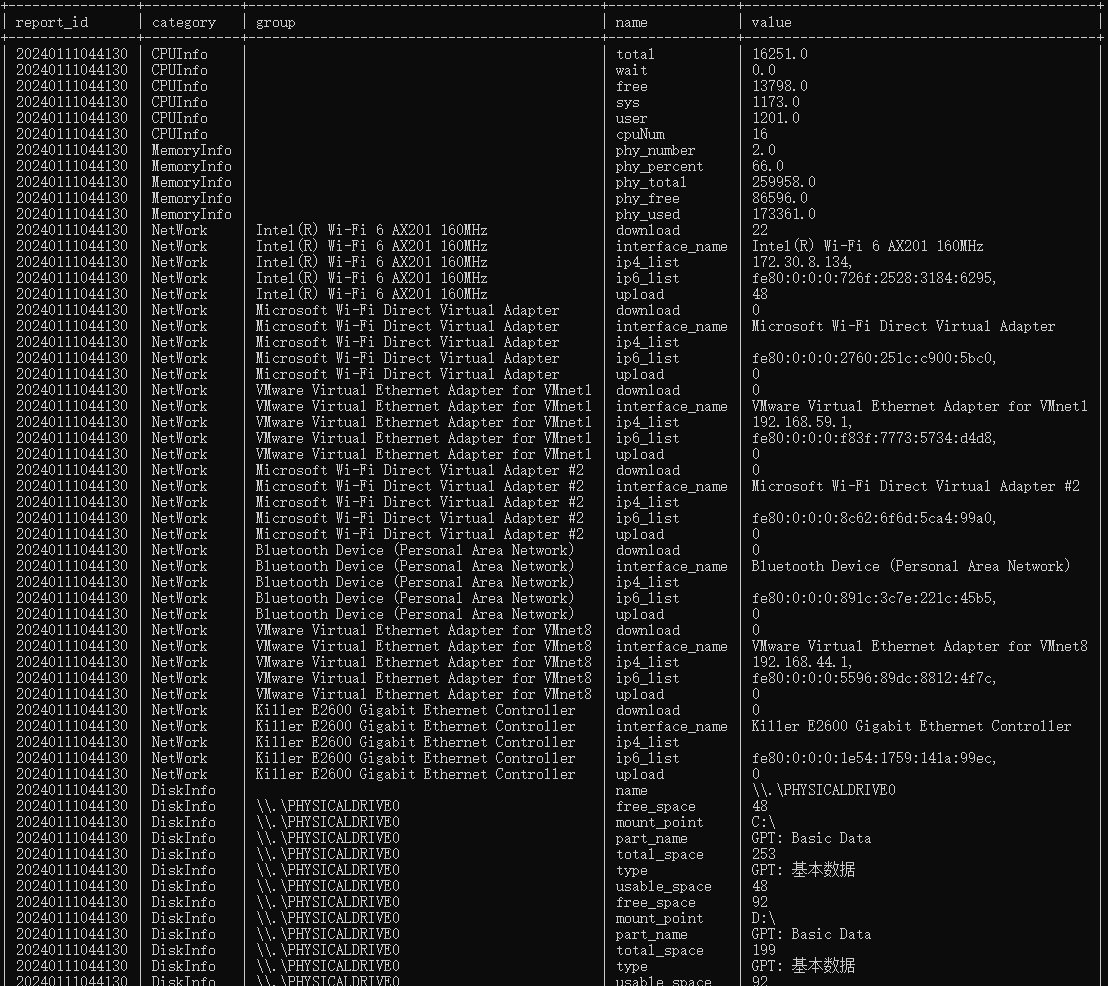 # 思路一(⭐) 设计成k-v模式,也就是说键值对模式,表格设计如下 | 时间(bigint) | 类别(varchar) | 组(varchar) | 名称(varchar) | 值(varchar) | | --- | --- | --- | --- | --- | | 20240111171329 | CPU信息 | null | 系统使用率 | 10.3% | | 20240111171329 | CPU信息 | null | 用户使用率 | 13.6% | | 20240111171329 | CPU信息 | null | 空闲率 | 76.1% | | 20240111171329 | 内存信息 | null | 接口使用数 | 2 | | 20240111171329 | 内存信息 | null | 内存使用容量 | 173361.0 | | 20240111171329 | 内存信息 | null | 内存剩余容量 | 86596.0 | | ... | ... | ... | ... | ... | | 20240111171329 | 网卡信息 | | 上传速度 | 86596.0 | | 20240111171329 | 网卡信息 | Intel(R) Wi-Fi 6 AX201 160MHz | 上传速率 | 28kb/s | | 20240111171329 | 网卡信息 | Intel(R) Wi-Fi 6 AX201 160MHz | 下载速率度 | 89kb/s | | 20240111171329 | 网卡信息 | Intel(R) Wi-Fi 6 AX201 160MHz | 接口名称 | Intel(R) Wi-Fi 6 AX201 160MHz | | 20240111171329 | 网卡信息 | Intel(R) Wi-Fi 6 AX201 160MHz | IP地址 | 172.30.8.134 | | 20240111171329 | 网卡信息 | Killer E2600 Gigabit Ethernet Controller | 上传速率 | 0kb/s | | 20240111171329 | 网卡信息 | Killer E2600 Gigabit Ethernet Controller | 下载速率 | 0kb/s | | 20240111171329 | 网卡信息 | Killer E2600 Gigabit Ethernet Controller | 接口名称 | Killer E2600 Gigabit Ethernet Controller| | 20240111171329 | 网卡信息 | Killer E2600 Gigabit Ethernet Controller | IP地址 | 172.30.8.134 | | ... | ... | ... | ... | ... | 缺点:对于计算和后续的数据处理稍微有些难度 # 思路二 定义多张表(防止字段超出范围)和自定义字段,在程序中检查字段,如果不存在,则新增字段 ```sql SELECT * FROM information_schema.columns where TABLE_SCHEMA='csm' AND TABLE_NAME = 'system_info' -- 查询表格有哪些字段 ALTER TABLE `csm`.`system_info` ADD COLUMN `Intel(R) Wi-Fi 6 AX201 160MHz upload` varchar(255) NULL AFTER `value`; -- 添加字段 ``` 缺点:程序代码复杂,数据量大的表处理起来比较耗时 # 思路三 使用JSON字段存储结果 | 数据时间 | JSON值 | | --- | --- | | 20240111172625 | {"CPU系统使用率":"10.3","CPU用户使用率":"13.6","CPU空闲率":"76.1","Intel(R) Wi-Fi 6 AX201 160MHz 上传速率":"23.45kb/s","Intel(R) Wi-Fi 6 AX201 160MHz 下载速率":"21.45kb.s","...":"..."} | | 20240111172725 | {"CPU系统使用率":"10.3","CPU用户使用率":"13.6","CPU空闲率":"76.1","Intel(R) Wi-Fi 6 AX201 160MHz 上传速率":"23.45kb/s","Intel(R) Wi-Fi 6 AX201 160MHz 下载速率":"21.45kb.s","...":"..."} | 缺点:数据不直观,查询效率低 ## MySQL的JSON操作 ```json CREATE TABLE `json_test` ( `id` int NOT NULL, `content` json DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ``` | id | content | | ---- | -------------------- | | 1 | {"a": "a", "b": 4} | | 2 | {"a": "b", "b": 44} | | 3 | {"a": "c", "b": 333} | ```sql SELECT * FROM test.json_test where content->'$.a' = 'b' SELECT * FROM test.json_test where content->'$.b' > 15 ``` # 针对于思路一的Java处理 ## 0x01 定义数据库 entity ``` @Data @AllArgsConstructor @NoArgsConstructor @ToString public class InfoEntity { private Long report_id; private String category; private String group; private String name; private String value; } ``` ## 0x02 创建结果集列表 ``` List<InfoEntity> result = new ArrayList<>(); ``` ## 0x03 把entity转成HashMap ```java JSONObject.parseObject(JSONObject.toJSONString(cpuInfo)) // fastjson ``` ## 0x04 遍历map的entrySet ``` for (HashMap<String, Object> item : data) { ... } ``` ## 0x05 把遍历的实体set到实体对象 ```java result.add(new InfoEntity(dateid, category, group, key, value)); ``` ## 0x06 mybatis生成sql ```xml <insert id="appendRecords" parameterType="java.util.ArrayList"> INSERT INTO system_info(`report_id`, `category`, `group`, `name`, `value`) values <foreach collection="list" item="item" index="index" separator=","> (${item.report_id}, #{item.category}, #{item.group}, #{item.name}, #{item.value} ) </foreach> </insert> ``` # 结语 不同思路都有各自的优势和劣势,只要能完美的处理业务数据,那就是好的解决方案。 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏

1 条评论
不愧是你