Loading... # 引言 今天一个朋友提了个需求,说是把视频中的文字给提取出来,用于做会议总结,可是视频太长了,网上的好多都是收费的,挺令人苦恼的,所以用OpenAI开源的Whisper处理也是个不错的选择,但是最好是有GPU的机器,不然会很慢的。 # 环境构造 官网: https://github.com/openai/whisper - python3 从Github上拉下来源码,用python编译安装,如果没有虚拟环境(如anaconda),可以Pipenv来生成一个崭新的python环境。 使用新环境中的`python` 执行`python setup.py install`  ## GPU支持(N卡) pytorch: https://pytorch.org/get-started/locally/ ```python import torch version__ = torch.__version__ print(version__) available = torch.cuda.is_available() print(available) # 如果是True 则支持 ``` 这里需要和自己CUDA对应上,如果没有,选择最相近的就行。 比如我的 ```bash C:\Users\*****>nvidia-smi Thu Dec 28 18:30:09 2023 +---------------------------------------------------------------------------------------+ | NVIDIA-SMI 546.33 Driver Version: 546.33 CUDA Version: 12.3 | |-----------------------------------------+----------------------+----------------------+ | GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 NVIDIA GeForce RTX 3060 ... WDDM | 00000000:01:00.0 Off | N/A | | N/A 76C P0 75W / 115W | 4885MiB / 6144MiB | 53% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| | 0 N/A N/A 42432 C E:\Software\python310\python.exe N/A | +---------------------------------------------------------------------------------------+ ``` 我用的是`pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118` 是可以完美运行的,可做参考。 # 运行 路径:venv/Scripts/whisper.exe ``` whisper audio.wav --model medium --language Chinese ``` 这时候会自动下载模型包,路径为`C:\Users\[Users]\.cache\whisper` 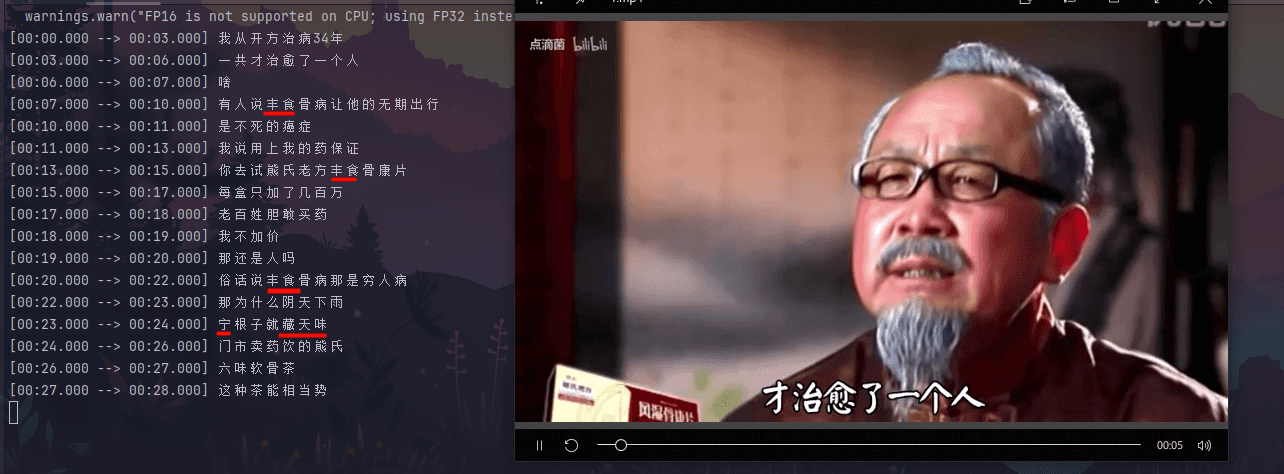 ## demo ```python import whisper wr = whisper.load_model("medium") transcribe = wr.transcribe('audio.wav', initial_prompt='这是普通话的句子。') # 这样结果是简体的,并且有标点符号的,注意最后的句号 print(transcribe) ``` © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
