Loading... # 链接 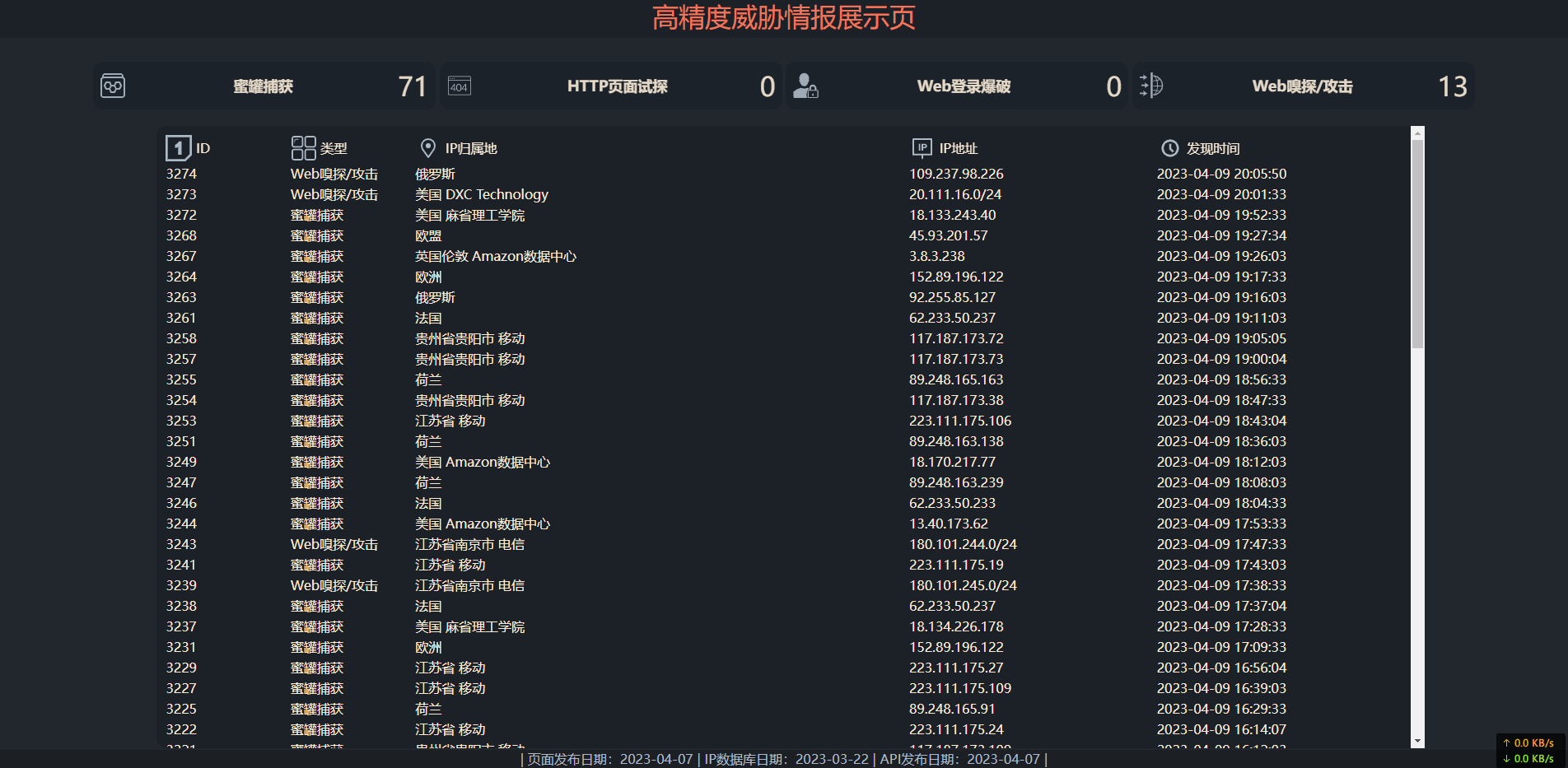 [高精度威胁情报展示页](https://www.zunmx.top/report/) # 感想 最初想法是简约一点的,大概分为几个方向 - 蜜罐系统 - web日志分析 - 404页记录器 毋庸置疑的,蜜罐系统就是不存在的服务,这些服务仅仅是监听了一些端口,谁访问,就记录谁。  web日志分析,比如说爬虫涉及到的UA信息,不可能存在的页面,访问莫名其妙的uri,比如说 UA信息:`zgrab/0.x` `python-requests/` 请求方式:`CONNECT` 访问路径:`ip.zip` `backup.zip` `www.zip` `web.zip` 相同IP或同C段的IP短时间内触发了大量的404请求,那么他们很大概率的就是扫描了。 # 疑问 比如说下面这些log,我明明没有这些页面,为什么日志的状态码是200?这样对于我404页的分析产生了很严重的问题 ```bash 20.111.16.183 - - [09/Apr/2023:20:01:18 +0800] "GET /wso.php HTTP/1.1" 200 938 "-" "python-requests/2.27.1" 20.111.16.183 - - [09/Apr/2023:20:01:19 +0800] "GET /wp-content/plugins/upspy/index.php HTTP/1.1" 200 938 "-" "python-requests/2.27.1" 20.111.16.183 - - [09/Apr/2023:20:01:20 +0800] "GET /wp-content/plugins/ubh/index.php HTTP/1.1" 200 938 "-" "python-requests/2.27.1" 20.111.16.183 - - [09/Apr/2023:20:01:21 +0800] "GET /wp-content/plugins/vwcleanerplugin/bump.php?cache HTTP/1.1" 200 938 "-" "python-requests/2.27.1" 20.111.16.183 - - [09/Apr/2023:20:01:22 +0800] "GET /wp-content/plugins/xichang/x.php?xi HTTP/1.1" 200 938 "-" "python-requests/2.27.1" 20.111.16.183 - - [09/Apr/2023:20:01:23 +0800] "GET /wp-content/plugins/html404/index.html HTTP/1.1" 200 938 "-" "python-requests/2.27.1" ``` # 涉及到的相关文章 ## 纯真IP解析 <div class="preview"> <div class="post-inser post box-shadow-wrap-normal"> <a href="https://www.zunmx.top/archives/1632/" target="_blank" class="post_inser_a no-external-link no-underline-link"> <div class="inner-image bg" style="background-image: url(https://www.zunmx.top/usr/uploads/2023/02/2271853224.png);background-size: cover;"></div> <div class="inner-content" > <p class="inser-title">cz88 纯真库自动化下载及解析 (2023年初适用)</p> <div class="inster-summary text-muted"> 引言本片文章为之前写的文章的补充版,这里附上了解析操作的代码,最终结果可以自行格式化,写入数据库或者其他位置。准备... </div> </div> </a> <!-- .inner-content #####--> </div> <!-- .post-inser ####--> </div> ## 更优先的防火墙 <div class="preview"> <div class="post-inser post box-shadow-wrap-normal"> <a href="https://www.zunmx.top/archives/1730/" target="_blank" class="post_inser_a no-external-link no-underline-link"> <div class="inner-image bg" style="background-image: url(https://www.zunmx.top/usr/themes/handsome/assets/img/sj/1.jpg);background-size: cover;"></div> <div class="inner-content" > <p class="inser-title">腾讯云防火墙API利用</p> <div class="inster-summary text-muted"> 引言官方提供了API,剩下的主动型还是被动式的可以自己去开发了。但是狗血的是,每台轻量级服务器只能设置100个规则... </div> </div> </a> <!-- .inner-content #####--> </div> <!-- .post-inser ####--> </div> # 其它 是不是可以通过这些数据,分析总结出一份彩虹表呢? # 更加疑惑的事情 周五那天我写了一个页面,这个页面并没有在其他地方引用,我只想自己访问,并且文件名足够隐蔽,但是在web的访问日志中却发现了并非我的IP访问的记录。 难道服务器被安插后门或是存在0day漏洞?他们是如何检测到我的这个页面的? 还有一个,就是为了方便,我有一个页面是通过简单的GET请求进行登录验证的。比如说login.cgi?passwd=123456 其中会对passwd进行校验,并非走的数据库,直接存在了application里了,当然,这个密码肯定不是123456,这个页面也已经被我用更加保险的方式进行认证了。 昨天查看web服务器的日志,却惊到我了,还是有人可以访问这个页面,并且get请求的参数日志中是可见的,密码也是正确的,更有甚者,refer部分是正确的uri和密码,但是get请求的路径是错的。赤裸裸的挑衅啊。 其实那个页面并不涉及高敏感数据,只是一些服务器信息和常用的电脑的内网IP和无线连接情况。并不能作为肉鸡呀,大佬们求放过。🙏 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
