Loading... # 引言 因为工作需要,引入自动化脚本,原先手工生成的文本数据,现在通过代码生成,为了保证代码生成的和手工生成的一致性,故写此脚本。 ⚠ 文本顺序不影响最终结果,如果要完全一致,则直接考虑md5即可。 # 步骤 1. 读入文件 2. 分割换行 3. 去除空行 4. 排序 5. 生成新文件 6. 计算md5 7. 输出结果 # 技术 1. sort 2. hashlib # 代码 ```python import hashlib print("[i] Read text file and output sorted file") print("[!] Warning new file will del(ignored) blank lines") file = "%" files_list = [] while True: file = input("[#] File:> ") if file == "": break files_list.append(file) result = "" with open(file, 'r') as f: text = f.read() lines = text.split("\n") for i in range(len(lines)): if lines[i] == "": del lines[i] lines.sort() with open(file + "new", 'w') as f: f.write("\n".join(lines)) md5 = [] name_max_len = 0 for new_file in files_list: name_max_len = max(name_max_len, len(new_file)) file_name = new_file + "new" with open(file_name, 'r') as f: text = f.read() md5.append(hashlib.md5(bytes(text, encoding='utf-8')).hexdigest()) print("[i] " + "-" * (name_max_len + 35)) fm = "[i] " + "|{:^32s}|{:^" + str(name_max_len) + "}|" print(fm.format("md5", "file")) print("[i] " + "-" * (name_max_len + 35)) fm = "[i] " + "|{:^32s}|{:<" + str(name_max_len) + "}|" for i in range(len(md5)): print(fm.format(md5[i], files_list[i])) print("[i] " + "-" * (name_max_len + 35)) print("[i] " + "Result: " + "√ Exactly consistent" if len(set(md5)) == 1 else "× Not exactly consistent") ``` # 效果 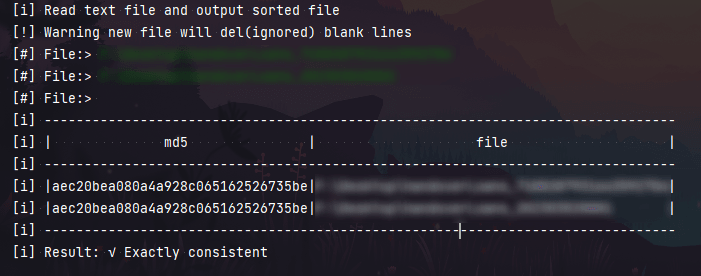 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
